摘要
如何打造出色的 Elasticsearch mapping?动态 mapping 可以灵活应对不同数据类型,但也可能会影响性能。显式 mapping 可以关闭动态 mapping,确保数据类型的准确性。
正文
怎样设计方案一个性能卓越 Elasticsearch mapping
文件目录
- 序言
- mapping
- mapping 能干什么
- Dynamic mapping
- dynamic=true
- dynamic=runtime
- dynamic=false
- dynamic=strict
- 是不是能够 改动 mapping 中的基本数据类型
- 关掉 dynamic mapping
- Explicit mapping
- text 种类
- keyword 种类
- date 种类
- numeric 种类
- boolean 种类
- 其他类型
- 汇总
序言
在关联型概念模型设计之中,表的设计方案特别是在关键,殊不知关联型数据库查询更关心的表与表中间的关联,及其表的区划是不是有效,而 Elasticsearch 中却更为关心字段名种类的设计方案,一个好的字段种类设计方案能够 更强的运用 Elasticsearch 的检索剖析特点。
mapping
假如说大家要想用好 Elasticsearch,那麼就务必要先掌握 mapping 什么叫 mapping。一句话:mapping是界定怎样储存和数据库索引文本文档以及包括的字段名的全过程。
mapping 能干什么
前边大家提及,在 Elasticsearch 中,mapping 类似传统式关联型数据库查询的表构造界定,关键做下列一些事:
- 界定字段名称和字段名种类。
- 界定全文索引有关的配备,例如是不是被数据库索引,是不是能够 被词性标注等。
mapping 能够 分成二种:Dynamic mapping 和 Explicit mapping。
Dynamic mapping
Dynamic mapping 即:动态性投射。动态性投射说白了便是 mapping 会被实例化,换句话说大家不用界定 mapping 就可以往一个数据库索引插进数据信息,插进数据库索引数据信息以后,Elasticsearch 会依据插进的数据信息全自动推断基本数据类型,从而动建立 mapping。
例如下边便是往一个不会有的数据库索引 index_001 插进一条数据信息:
PUT index_001/_doc/1
{
"name":"lonely wolf",
"age": 18,
"create_date":"2021-05-19 20:45:11",
"update_date":"2021-05-23"
}
插进数据信息以后,实行 GET index_001 来查看一下数据库索引信息内容:
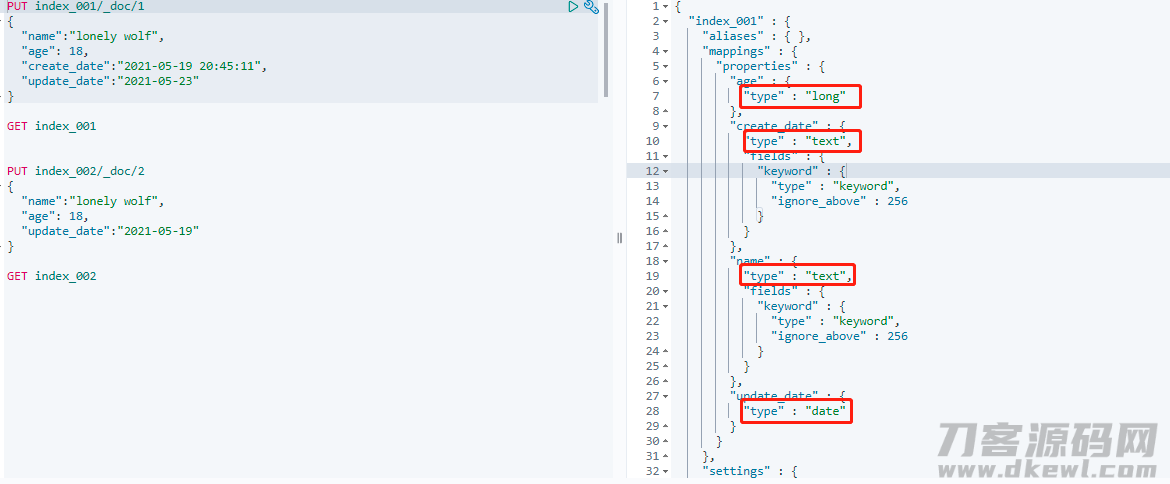
能够 发觉,此刻数据库索引早已被全自动建立了,并且 age 字段名被 Elasticsearch 界定为 long 种类,update_date 被界定为 data 种类,别的2个字段名则被推断为 text 种类。
Elasticsearch 中全自动投射种类标准能够 根据 dynamic 主要参数开展配备,dynamic 种类有 4 种:
dynamic=true
初始值。当设定为 true 时,一旦有新字段插进文本文档,则 mapping 会被同歩升级。
大家在上面的文本文档中再插进一个新文本文档,新文本文档增加一个 address 字段名:
PUT index_001/_doc/2
{
"name":"lonely wolf2",
"age": 20,
"create_date":"2021-05-23 11:37:11",
"update_date":"2021-05-23",
"address":"广东省深圳市"
}
随后再查询一下 mapping,能够 见到 mapping 早已增加了一个 address 字段名,mapping 字段名被升级代表着该字段名会添加数据库索引:

dynamic=runtime
这一种类和 true 种类十分类似,可是有一个十分大的差别便是,尽管添加新字段也会升级 mapping,可是新添加的字段名不容易被数据库索引,也就是不容易促使数据库索引增大,但是尽管不被数据库索引,可是新添加的字段依然能够 被查看,仅仅查看的成本会更高。因此 这类种类一般不建议用在常常查看的标准字段名上,而更合适用在一些不确定性算法设计的日志类数据库索引中。
改动 dynamic 种类:
PUT index_001/_mapping
{
"dynamic": "runtime"
}
增加一个文本文档,并添加一个新字段:
PUT index_001/_doc/3
{
"email":"123@qq.com"
}
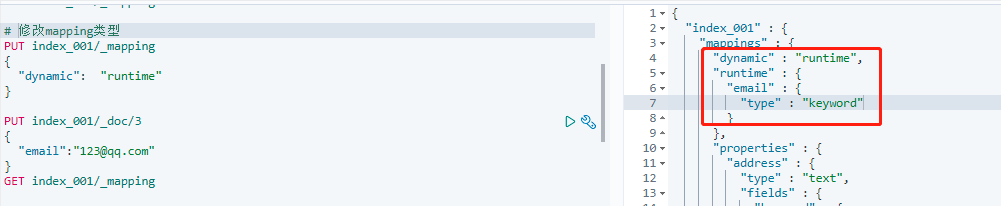
最终询一下 mapping,能够 见到字段名特性是 runtime,并且种类是 keyword:
下表便是全自动建立 mapping 时,Elasticsearch 的投射关联:
| 插进基本数据类型 | dynamic=true | dynamic=runtime |
|---|---|---|
| null | 不容易加上一切字段名 | 不容易加上一切字段名 |
| true 或 false | boolean | boolean |
| double | float | double |
| integer | long | long |
| object | object | object |
| string(根据 date 校检) | date | date |
| string(根据 numreic 校检) | float 或 long | double 或 long |
| string(沒有根据 date 或 numreic 校检) | text ,而且另外会建立一个 keyword 子域 | keyword |
| array | 在于二维数组中第一个非 null 值 | 在于二维数组中第一个非 null 值 |
PS:keyword 表明 不参加词性标注。
dynamic=false
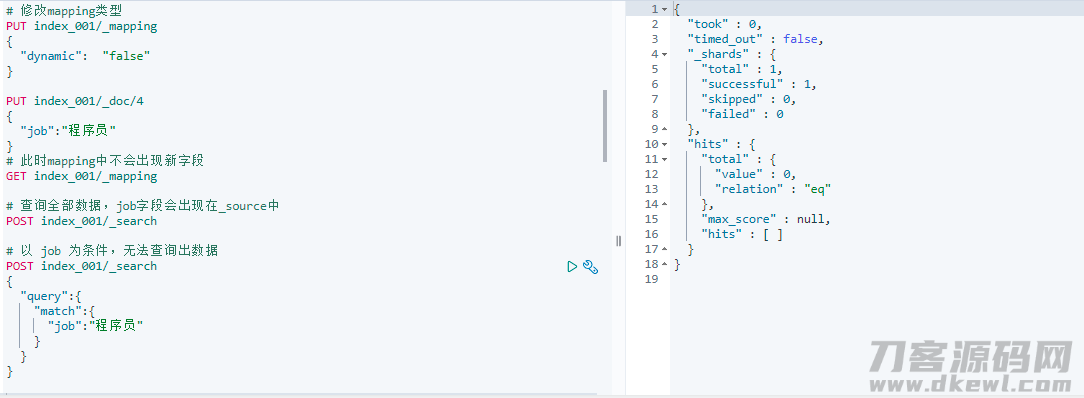
当设定为 false 时,新添加的字段名不容易被升级到 mapping,换句话说新字段不容易被数据库索引,故以这一字段名为标准开展检索时,没法被检索到(这一点要留意和 runtime 种类开展区别),但是尽管没法被数据库索引,可是该字段名会发生在 _source 中。换句话说该字段名不可以做为查询条件,可是能被查看出去。
下面大家将 dynamic 改动为 false,并增加一个字段名来认证,能够 发觉增加的字段名会发生在 _source 中,可是没法做为标准被查看出去:
dynamic=strict
这类种类更为严苛,表明不允许增加一个没有 mapping 中的字段名,一旦增加的字段名没有 mapping 界定中,则立即出错:

是不是能够 改动 mapping 中的基本数据类型
在 Elasticsearch 中,一旦一个字段名被界定在了 mapping 中,是没法被改动的,由于一旦字段名被改动了,便会没法被数据库索引(增加字段名以外),因此 一般大家必须改动数据库索引得话,都是会复建数据库索引,并选用 reindex 实际操作来转移数据信息。
关掉 dynamic mapping
能够 根据下列2个配备来关掉 dynamic mapping,下列2个特性初始值均为 true,假如必须关掉,则必须改动为 false:
action.auto_create_index: true
index.mapper.dynamic: true
Explicit mapping
Explicit mapping 即:显式投射。换句话说此刻大家必须表明的界定字段名种类。
Elasticsearch 中适用的字段名种类许多,在这儿就举一些较为常见的字段名种类:
text 种类
它是最常见的一种种类,储存字符串数组,用以全文索引。当字段名被界定为 text 种类时,默认设置不可以用以汇聚,排列等实际操作:
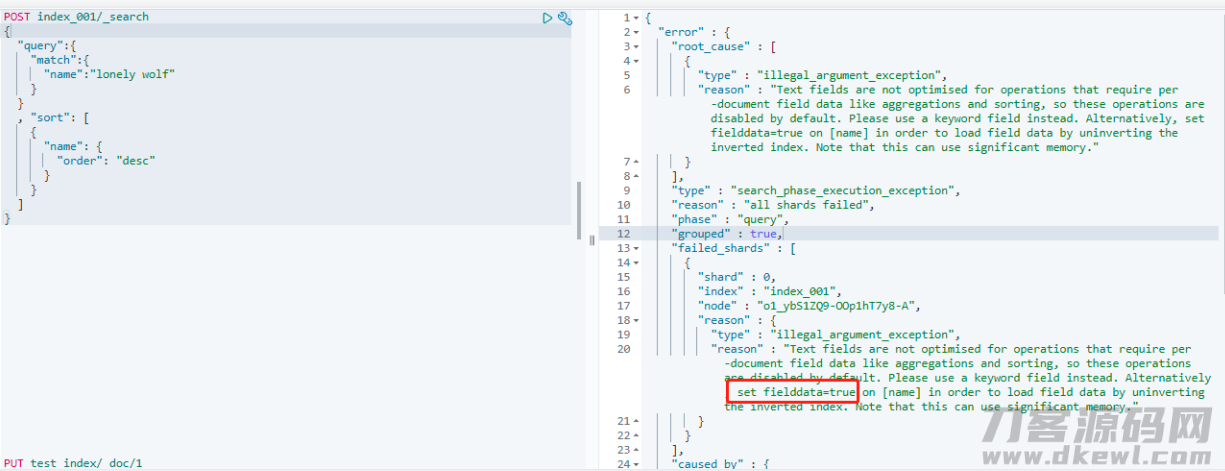
能够 见到,用 text 种类字段名排列报告凑,假如要想容许这种实际操作,能够 根据设定 fielddata=true,以下
PUT my-index-011/_mapping
{
"properties": {
"my_field": {
"type": "text",
"fielddata": true
}
}
}
field 字段名储存在堆内存中,由于其牵涉到的测算较为耗费特性,因此 一般不建议设定 fielddata=true,只是根据创建一个 keyword 子域来完成(默认设置方法):
PUT index_111
{
"mappings": {
"properties": {
"my_field": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword"
}
}
}
}
}
}
这类界定方法我们可以将一个字段名另外做为 text 和 keyword 种类应用,假如要用以汇聚或是排列等实际操作则能够 应用 字段名.keyword 来做为字段名来开展实际操作:
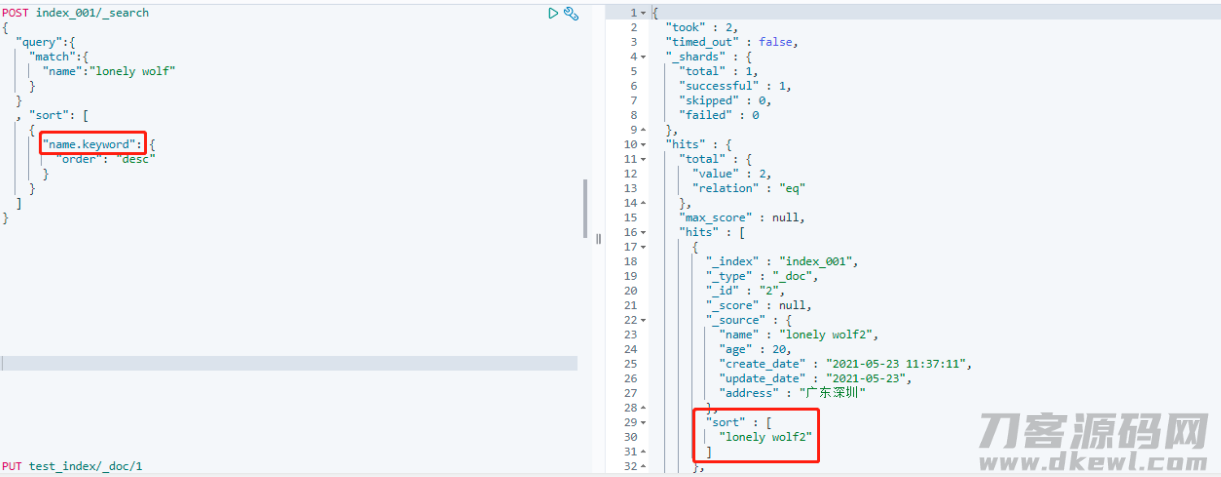
keyword 种类
这类种类也十分常见,该字段名储存的数指一个总体,不能被词性标注,因此 一般不容易用于界定大文中的全文搜索字段名,只是用于储存一些结构型的字符串数组,例如:id,电子邮箱,标识等。
keyword 种类一般用以汇聚,排列等实际操作。此外,该字段名也有二种衍化种类:constant_keyword 和 wildcard。
constant_keyword:一般用以界定变量定义种类,例如一个数据库索引中某一个字段名所有为同一个值,能够 界定为这类种类。wildcard:一般用以模糊匹配查看或是正则匹配查看。
以下便是一个模糊匹配查看的实例(能够 相互配合使用通配符应用,类似关联型数据库查询的 like 实际操作):
GET index_112/_search
{
"query": {
"wildcard": {
"my_wildcard": {
"value": "*quite*lengthy"
}
}
}
}
date 种类
用以界定日期种类,界定日期种类的另外,能够 根据 format 来特定日期的文件格式:
PUT index_113
{
"mappings": {
"properties": {
"date": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis" }
}
}
}
numeric 种类
Elasticsearch 中给予了比较多的文件格式用于表明不一样长短的数据种类:
| 数据种类 | 长短 |
|---|---|
| long | 64 位有标记整数金额。范畴:-2 的 63 三次方到 2 的 63 三次方 -1 |
| integer | 32 位有标记整数金额。范畴:-2 的 31 三次方到 2 的 31 三次方 -1 |
| short | 16 位有标记整数金额。范畴:-32768 到 32767 |
| byte | 8 位有标记整数金额。范畴:-128 到 127 |
| double | 64 位双精度小数 |
| float | 32 位单精度小数 |
| half_float | 16 位单精度小数 |
| scaled_float | 含有放缩因素的浮点型,一般适用储放额度这类的数据信息。例如 18.88 元,放缩因素是 100,那麼在数据库索引的时候会被数据库索引为 1888(即:原值 * 放缩因素) |
| unsigned_long | 64 位无符号整数。范畴:0 到 2 的 64 三次方减 1 |
界定方法以下所显示:
PUT index_002
{
"mappings": {
"properties": {
"number_of_bytes": {
"type": "integer"
},
"time_in_seconds": {
"type": "float"
},
"price": {
"type": "scaled_float",
"scaling_factor": 100
}
}
}
}
boolean 种类
布尔类型非常简单,仅有 true 和 false 二种:
PUT index_001
{
"mappings": {
"properties": {
"is_published": {
"type": "boolean"
}
}
}
}
其他类型
除开上边详细介绍的一些较为常见的基本数据类型,Elasticsearch 中也有一些高級基本数据类型:如 Nested(嵌入种类),自然地理基本数据类型,ip 种类等。
汇总
Elasticsearch 中适用动态性 mapping 和表明 mapping 二种,在应用中有时能够 先插进一条数据信息到临时性数据库索引,等自动生成 mapping 以后,在对目前 mapping 开展改动调节,在字段名上特别是在要考虑到好 text 种类和 keyword 种类的设定,假如必须适用全文检索和词性标注检索,则必须应用 text 种类,必须适用关键词模糊查询或是汇聚排列等实际操作能够 考虑到应用 keyword 字段名。
关注不迷路
扫码下方二维码,关注宇凡盒子公众号,免费获取最新技术内幕!








评论0